It was good for like, one month. Qwen3 30b dominated for half a year before that, and GLM-4.7 Flash 30b took over the crown soon after Nemotron 3 Nano came out. There was basically no time period for it to shine.
It is still good, even if not the new hotness. But I understand your point.
It isn't as though GLM-4.7 Flash is significantly better, and honestly, I have had poor experiences with it (and yes, always the latest llama.cpp and the updated GGUFs).
That seems like a nonissue for the purposes of this discussion though, in terms of user uptake. Tiktok and Facebook and other websites aren't exactly focused on serving to people on the same network.
It's really easy to run this in a container. The upside is you get a lot of protection included. The downside is you're rebuilding the container to add binaries. The latter seems like a fair tradeoff.
What I'll say about OpenClaw is that it truly feels vibe coded, I say that in a negative context. It just doesn't feel well put together like OpenCode does. And it definitely doesn't handle context overruns as well. Ultimately I think the agent implementation in n8n is better done and provides far more safeguards and extensibility. But I get it - OpenClaw is supposed to run on your machine. For me, though, if I have an assistant/agent I want it to just live in those chat apps. At that rate it's running in a container on a VPS or LXC in my home lab. This is where a powerful-enough local machine does make sense and I can see why folks were buying Mac Minis for this. But, given the quality of the project, again in my opinion, it's nothing spectacular in terms of what it can do at this point. And in some cases it's more clunky given its UI compared to other options that exist which provide the same functionality.
The thing is running it onto your machine is kinda the point. These agents are meant to operate at the same level - and perhaps replace - your mail agent and file navigator. So if we sandbox too much we make it useless.
The compromise being having separate folders for AI, a bit like having a Dropbox folder on your machine with some subfolders being personal, shared, readonly etc.
Running terminal commands is usually just a bad idea though in this case, you'd want to disable that and instead fine tune a very well configured MCP server that runs the commands with a minimal blast radius.
> running it onto your machine is kinda the point.
That very much depends what you're using it for. If you're one of the overly advertised cases of someone who needs an ai to manage inbox, calendar and scheduling tasks, sure maybe that makes sense on your own machine if you aren't capable of setting up access on another one.
For anything else it has no need to be on your machine. Most things are cloud based these days, and granting read access to git repos, google docs, etc is trivial.
I really dont get the insane focus around 'your inbox' this whole thing has, that's perhaps the biggest waste of use you could have for a tool like this and an incredibly poor way of 'selling' it to people.
> someone who needs an ai to manage inbox, calendar and scheduling tasks
A secretary. The word you're looking for is "secretary". Having a secretary has always been the preferred way to handle these tasks for the wealthy and powerful. The president doesn't schedule his own meetings and manage his own Outlook calendar, a president/CEO/etc has better things to do.
People just created calendar/email/etc software (like Microsoft Outlook) to let us do it ourselves, because secretaries are $$$$. But let's be real, the ideal situation is having a perfect secretary to handle this crap. That's the point of using AI here: to have an AI secretary.
Managing your own calendar would become extremely 2010 coded, if AI secretaries become a thing. It'd be like how "rewinding your VCR tape" is 1990s coded.
Unless you're swamped with email I don't really get it. If someone calls me to arrange an appointment I say "Hey Google add x to calendar" after the call and it's done. Gemini can use Gmail and other workspace apps. You can also set up commands to do a few different things at once, like turning on the lights when you get home by saying I'm home. With any cheap set of bluetooth earphones this is all hands free.
Lots of these YouTubers are using openclaw to replace simple Google/Siri voice queries with something prohibitively complex, expensive and insecure.
Also, people in the 90's didn't have push notifications. We see emails on our watch/phone and can delete/archive/snooze from there. Email triage takes zero time these days and can be done from anywhere.
I do get it though if you're someone who is extremely busy and really needs a PA.
Much more likely that the average user is either unemployed or in the leisure class.
I don't know whether it's a part of the joke or not, but I do get a `alert(XSS)` when I load the site from something loaded from https://molt.church/api/canon
Time is the issue. Time spent training for Olympics can't necessarily be used to generate an income. The whole premise of this donation is to afford them time, which it doesn't.
FWIW, most athletes are already used to being frugal as they juggle an often expensive training schedule with their personal finances. This is being framed as giving them money to focus on their sport/event during their competitive years.
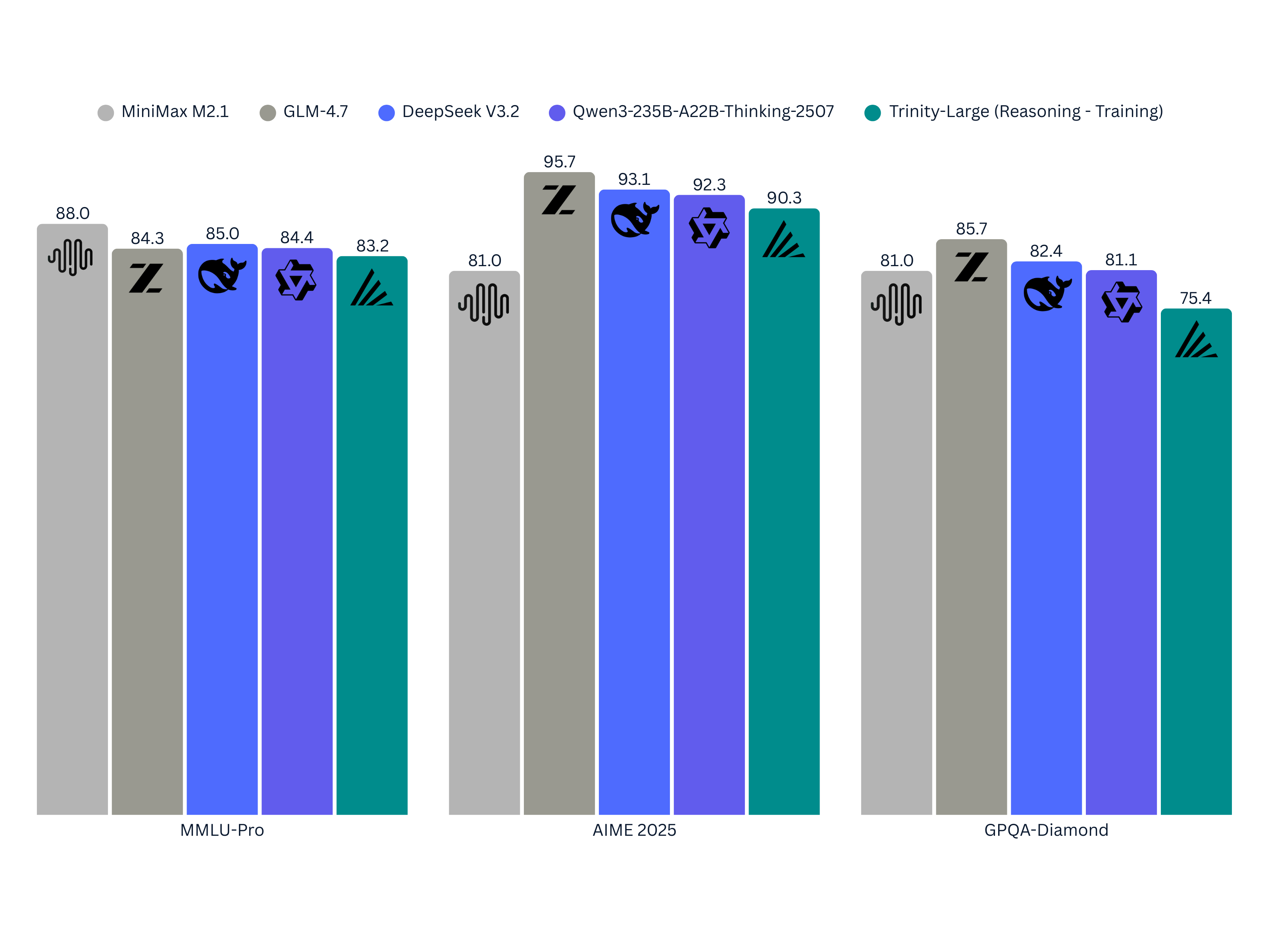
It's because they're doing 4 of 256 sparsity, which was a bad decision caused by financial limitations.
Training cost (FLOPs) = 6 * active params * total tokens. By keeping the MoE experts param count low, it reduces total training costs.
I don't think this was a good move. They should have just trained way past chinchilla like the other major labs, and keep sparsity above 2%. Even Kimi K2 is above 2%. GLM is at 5%, which makes it very expensive (and high performing) for its small size.
Arcee went the other way. They trained a massive 400b model (bigger than GLM-4.5/4.6/4.7, bigger than Qwen3 235b A23b), but only have 17b active params, which is smaller than Qwen and GLM. It's also only trained on 17T tokens, vs 20-30T+ tokens for the other models. It's just undertrained and undersized (in terms of active parameters), and they got much worse performance than those models:
It's not a bad showing considering the limitations they were working with, but yeah they definitely need double the active experts (8 out of 256 instead of 4 out of 256) to be competitive. That would roughly double the compute cost for them, though.
Their market strategy right now is to have less active params so it's cheaper for inference, more total params so it's smarter for the amount of active params they have, but not too big to fit into a H200 cluster. I... guess this is a valid niche strategy? The target audience is basically "people who don't need all the intelligence of GLM/Qwen/Deepseek, but want to serve more customers on the H200 cluster they already have sitting around". It's a valid niche, but a pretty small one.
128GB vram gets you enough space for 256B sized models. But 400B is too big for the DGX Spark, unless you connect 2 of them together and use tensor parallel.
Yeah. Example: stripper poles. Or hitachi magic wands.
Those poles WERE NOT invented for strippers/pole dancers. Ditto for the hitachis. Even now, I'm pretty sure more firemen use the poles than strippers. But that doesn't stop the association from forming. That doesn't make me not feel a certain way if I see a stripper pole or a hitachi magic wand in your living room.
They didn't do something stupid like Llama 4 "one active expert", but 4 of 256 is very sparse. It's not going to get close to Deepseek or GLM level performance unless they trained on the benchmarks.
I don't think that was a good move. No other models do this.
{kind=link}
reply