> we use the identifier p to represent a value in the people slice — the range block is so small and tight that using a single letter name is clear enough.
No, it's not. When you see `p.Age`, you have to go back and find the body of the loop, see what it operates on and decipher what p stands for. When you see `person.Age`, you understand it. I've never understood what is gained by using `p` instead of spelling it out as `person`.
>you have to go back and find the body of the loop
If the loop is long enough that you don't naturally remember how it was introduced, that's the problem. In the given example, the use of `p.Age` is literally on the next line of code after ` for _, p := range people`.
> I've never understood what is gained by using `p` instead of spelling it out as `person`.
Wisdom I received from, IIRC, the Perl documentation decades ago: tightly-scoped names should be shorter and less attention-grabbing than more broadly-scoped ones, because you should really notice when you're using a global, and you don't want to suffer attention fatigue. (I'm sure the exact wording was quite different.)
Also because it's better for information density. As I recall, Larry Wall also had the idea that more commonly used language keywords should be shorter than rare ones. Good code uses the locals much more often than globals, so you shouldn't need to expend the same amount of effort on them. (The limiting case of this is functional programming idioms where you can eliminate the variable name completely, in cases like (Python examples) `lambda x: int(x)` -> `int`, or `(foo(x) for x in xs)` -> `map(foo, xs)`.
The problem is that many times I have not read the definition to remember. Debugger puts me into a context where I have to figure out what `p` stands for. I go up the call stack and now there's `s` to be deciphered. Worse is the reuse of `p` for person, product, part, etc. in different contexts.
Debugging is not the only problem. Code is read rarely linearly. Many times I browse different uses of a function, or see how a data structure is modified in different contexts. Looking up single letter variables is just a waste of time.
This is a decent reason, but your original comment is dangerously close to a completely strawman argument of "the argument of the func AverageAge(people []Person) should be called peopleToCalculateTheAverageOfTheirAges because what if I forget the method's name or its purpose while I am reading its text?"
Which, now that I think of it, kinda applies to your argument as well. Yeah, the debugger dropped you into the middle of a function you see for the first time in your life. No matter how you dice it or slice it, this means you'll have to study this function; I personally find that going to the function's beginning and skimming it until the breakpoint is the most reliable (and therefore, on average, fastest) method.
I don't deny the trade-off between variable name length and other factors. But, between 1 and 38, I doubt that the optimal length is at 1. Adding 5 more letters doesn't take anything away, IMHO, while increasing comprehensibility significantly.
> Debugger puts me into a context where I have to figure out what `p` stands for.
`p` stands for "the process in question".
I like to think of single-character vars as idea or topic headers that track the single thing I'm currently up to. I'm rarely working with more than one at a time, frequently it's the only variable, and there are contexts where I wouldn't use them at all.
IMHO if you're in a situation where `p` isn't obvious to you, "something has gone wrong".
I've felt strongly for a while now that abbreviations should be "lossless" in order to be useful; it should be unambiguous now get back to the unabbreviated form. For whatever reason, people seem to love trying to optimize for character count with abbreviations that actually make things more confusing (like `res` in a context where it might mean either "response" or "result).
I just don't get the obsession with terseness when we have modern tooling. I don't type particularly fast, but autocomplete makes it pretty quick for me to type out even longer names, and any decent formatter will split up long lines automatically in a way that's usually sane (and in my experience, the times when it's annoying are usually due to something like a function with way too many arguments or people not wanting to put a subexpression in a separate variable because I guess they don't know that the compiler will just inline it) rather than the names being a few characters too many.
Meanwhile, pretty much everywhere I've worked has had at least some concerns about code reviews either already being or potentially becoming a burden on the team due to the amount of time and effort it takes to read through someone else's code. I feel like more emphasis on making code readable rather than just functional and quick to write would be a sensible thing to consider, but somehow it never seems to be part of the discussion.
> and any decent formatter will split up long lines
Any decent editor can wrap long lines on demand. But it's even better not to have to do either of those if not necessary.
> I've felt strongly for a while now that abbreviations should be "lossless" in order to be useful
This is how we got lpszClassName. The world moved away from hungarian notation and even away from defining types for variables in some contexts (auto in cpp, := in Go, var in Java). Often it just adds noise and makes it harder to understand the code at a glance, not easier.
I'd argue there's a stark difference between abbreviating words and adding extra ones. `p` as a shorthand for `person` is silly to me, but that doesn't mean that `personObject` would also be silly to me. I fundamentally don't agree with the premise that it's possible to be too verbose means that terseness is its own goal; the goal should be clarity, and I don't think that lossy abbreviations actually help with that except when someone already knows what the code is doing, in which case they don't need to read it in the first place.
Long lines make reading rhythm uncomfortable (long jumps, prolonged eye movements) and long words make the text too dense and slow down the reading. It’s bad typography.
I have heard an idea that a good variable should be understood by just reading its name, out of context. That would make “ProductIndex” superior to “i”, which doesn't add any clarity.
Something like "AnIteratorObjectWithPersonPointer" would be a long word, "person" is absolutely not. If a 6 letter identifier causes you that much trouble with code being too verbose, then it's likely a screen resolution/density/font issue, not a naming issue.
> That would make “ProductIndex” superior to “i”, which doesn't add any clarity.
And then you introduce extra two levels of nested loops and suddenly "i", "j", and "k" don't make any sense on their own, but "ProductIndex", "BatchIndex" and "SeriesIndex" do.
And then you introduce extra two levels of nested loops and suddenly "i", "j", and "k" don't make any sense on their own, but "ProductIndex", "BatchIndex" and "SeriesIndex" do.
ijk for indices in loops are actually clearer than random names in nested loops precisely because it is a *very common convention* and because they occur in a defined order. So you always know that "j" is the second nesting level, for instance. Which relates to the visual layout of the code.
You may not have known of this convention or you are unable to apply "the principle of least astonishment". A set of random names for indices is less useful because it communicates less and takes longer to comprehend.
Just like most humans do not read text one letter at a time, many programmers also do not read code as prose. They scan it rapidly looking at shapes and familiar structures. "ProductIndex", "BatchIndex" and "SeriesIndex" do not lend themselves to scanning, so you force people who need to understand the code to slow down to the speed of someone who reads code like they'd read prose. That is a bit amateurish.
> ijk for indices in loops are actually clearer than random names in nested loops precisely because it is a very common convention and because they occur in a defined order. So you always know that "j" is the second nesting level, for instance. Which relates to the visual layout of the code.
In problem domains that emphasize multidimensional arrays, yes.
More often nowadays I would see `i` and think "an element of some sequence whose name starts with i". (I tend to use `k` and `v` to iterate keys and values of dictionaries, but spell `item` in full. I couldn't tell you why.)
I partly agree, and partly don't. When ijk really is unambiguous and the order is common (say you're implementing a well-known algorithm) I totally agree, the convention aids understanding.
But nesting order often doesn't control critical semantics. Personally, it has much more often implied a heuristic about the lengths or types (map, array, linked list) of the collections (i.e. mild tuning for performance but not critical), and it could be done in any order with different surrounding code. There the letters are meaningless, or possibly worse because you can't expect that similar code elsewhere does things in the same nesting order.
I think I know what you mean. Let's assume a nesting structure like this:
Company -> Employee -> Device
That is, a company has a number of employees that have a number of devices, and you may want to traverse all cars. If you are not interested in where in the list/array/slice a given employee is, or a given device is, the index is essentually a throwaway variable. You just need it to address an entity. You're really interested in the Person structure -- not its position in a slice. So you'd assign it to a locally scoped variable (pointer or otherwise).
In Go you'd probably say something like:
for _, company := range companies {
for _, employee := range company.Employees {
for _, device := range employee.Devices
// ..do stuff
}
}
ignoring the indices completely and going for the thing you want (the entity, not its index).
Of course, there are places where you do care about the indices (since you might want to do arithmetic on them). For instance if you are doing image processing or work on dense tensors. Then using the convention borrowed from math tends to be not only convenient, but perhaps even expected.
A good variable name is the one that is understood by reading it in context, which is why you don't have names like "current_person" or "CurrentIndexOfProductBeingUpdated".
I think this may be related to how people read code. You have people who scan shapes, and then you have people who read code almost like prose.
I scan shapes. For me, working with people who read code is painful because their code tends to to have less clear "shapes" (more noise) and reads like more like a verbal description.
For instance, one thing I've noticed is the preference for "else if" rather than switch structures. Because they reason in terms of words. And convoluted logic that almost makes sense when you read it out loud, but not when you glance at it.
This is also where I tend to see unnecessarily verbose code like
func isZero(a int) bool {
if a == 0 {
return true
} else {
retur false
}
}
strictly speaking not wrong, but many times slower to absorb. (I think most developers screech to a halt and their brain goes "is there something funny going on in the logic here that would necessitate this?")
I deliberately chose to learn "scanning shapes" as the main way to orient myself because my first mentor showed me how you could navigate code much faster that way. (I'd see him rapidly skip around in source files and got curious how he would read that fast. Turns out he didn't. He just knew what shape the code he was looking for would be).
> strictly speaking not wrong, but many times slower to absorb. (I think most developers screech to a halt and their brain goes "is there something funny going on in the logic here that would necessitate this?")
I agree with this, but can't see how this applies to variable naming. Variable names can be too long, sure, but in my opinion, very short non-obvious variable names also make scanning and reading harder since they are not familiar shapes like more complete words. Additionally, when trying to understand more deeply, you have to stop and read code more often if variable's meaning is not clear.
That said, 1-2 char variable names work well in short scopes, like in some lambda, or when using 'i' for an index in a loop (nested loops would depend on situation), but those are an exception.
Like always, this is probably subjective too. And well-organized codebase probably helps to keep functions shorter, but there's often not much I can do about the existing codebase having overgrown functions all over.
> I think this may be related to how people read code. You have people who scan shapes, and then you have people who read code almost like prose.
I think this is an astute observation.
I think there is another category of "reading" that happens, is what you're reading for "interaction" or "isolation".
Sure c.method is a scalable shape but if your system deals with Cats, Camels, Cars, and Crabs that same c.method when dealing with an abstract api call divorced from the underlying representation might not be as helpful.
I would think that we would have more and better research on this, but the only paper I could find was this: https://arxiv.org/pdf/2110.00785 its a meta analysis of 57 other papers, a decent primer but nothing ground breaking here.
> I scan shapes. ... verbal description.
I would be curious if you frequently use a debugger? Because I tend to find the latter style much more useful (descriptive) in that context.
I think this is pretty insightful, and I might add this as another reason LLM code looks so revolting. It's basically writing prose in a different language, which make sense - it's a _language_ model, it has no structural comprehension to speak of.
Whereas I write code (and expect good code to be written) such that most information is represented structurally: in types, truth tables, shape of interfaces and control flow, etc.
and god help you if those loops are pairing People and Products.
though now that I write that out... it would be really nice if you could optionally type iteration vars so they couldn't be used on other collections / as plain integers. I haven't seen any languages that do that though, aside from it being difficult to do by accident in proof-oriented languages.
You usually don't need an index that can't be used elsewhere. If you don't then you can abstract it away entirely and use an iterator or foreach features.
Depends on the language. Doing that is a huge pain in Go (until fairly recently, and it's still quite abnormal or closure-heavy), so the vast majority of code there does manual index-pairing instead of e.g. a zip iterator when going through two paired arrays.
Tried to use the new slices package or comparables? It's a nightmare to debug, for no reason whatsoever. If they would've used interface names like Slice or Comparable or Stringable or something, it would have been so much easier.
The naming conventions are something that really fucks up my coding workflow, and it can be avoided 100% of the time if they would stop with those stupid variable names. I am not a machine, and there is no reason to make code intentionally unreadable.
This comes from some dated idea for stuff like C where "its okay to use shorthands for variables" but is it really? The only place I allow it is simple iterators, but now we have enhanced loops where even this is unnecessary. We don't need to save on pixel screen space like if its still the 90s. Even with a simple 1080p monitor you can fit plenty of words and code.
Give your variables, functions, classes meaningful descriptive names that make sense to humans.
Just because some brought it back to modern languages, doesn't mean it's not rooted in a practice from constrained hardware. I'd rather we name things what they mean.
I think this is clearly a matter of preference. Shorter variable (or rather, appropriately short variables for the context) for me are easier to recognize and disambiguate. They take up fewer tokens, so to speak. When I see `p.Age` I don't have to go back and look at the beginning of the loop because I just read that line and I remember it.
Furniture maker, house framer, finish carpenter are all under the category of woodworking, but these jobs are not the same. Years of honed skill in tool use makes working in the other categories possible, but quality and productivity will suffer.
Does working in JS, on the front end teach you how to code, it sure does. So does working in an embedded system. But these jobs might be further apart than any of the ones I highlighted in the previous category.
There are plenty of combinations of systems and languages where your rule about a screen just isn't going to apply. There are plenty of problems that make scenarios where "ugly loops" are a reality.
I didn't say it was an absolute. But once a scope grows to the point where you have to navigate to absorb a function or a loop, both readability and complexity tends to worsen. As does your mental processing time. Especially for people who "scan" code rapidly rather than reading it.
The slower "readers" will probably not mind as much.
This is why things like function size is usually part of coding standards at a company or on a project. (Look at Google, Linux etc)
Another point of view: ideally it would just be "Age". But in languages that don't have the ability to "open" scopes, one might be satisfied p.Age, being "the age". I've also seen $.age and it.age, in languages with constructs that automatically break out "it" anaphora.
This is something that it seems some Go people just don't "believe" in my experience, that for some people that letter in that context is not mentally populated immediately.
It's honestly a shame because it seems like Go is a good language but with such extremely opinionated style that is so unpleasant (not just single letters but other things stuff about tests aren't supposed to ever have helpers or test frameworks) feels aggressively bad enough to basically ruin the language for me.
I think the community is split on such things. I ended up telling the side that gets persnickety about short names and only using if statements in tests to pound sand. I use things that make my life easier. I now care less about some rude rando on r/golang than I did five years ago.
But what if your codebase has to interact with leads, customers, and another 3rd party system called Metrica with leads, customers?
When you write a loop, do you now name the variable
OurPerson.Age
MetricaPerson.Age
?
What if, 3 years from now, you include another 3rd party vendor into the system and have to write code against that data and in the data they name their stuff OurPerson.Age?
Not saying you are wrong at all. Just naming things is hard and context dependent. I think that is why it is endlessly argued.
I'm a a people. I read it. If you call this an unreadable mess I really don't know what to say. Language is awesome, and it's awesome we can create infinitely long sentences with it. And like open source, if you don't like it, write the one you like :)
A long time ago on the myspace forums there was this slightly weird but also very wise and smart person who wrote without any punctuation or paragraphs, ever. Although they were generally liked and part of the community, I think I was the only person who read every single one of their comments in full, religiously, once I realized how insightful they were, and I was richer for it. I could have told them the obvious, how their posts differ from most others on the forums; and they would have posted with less joy and maybe less overall, that would have been it.
While I don't agree with the other poster, that the comment was a mess, sentences were so long, that I had to focus not to lose the point. I think the top comment read a bit too much like stream of consciousness, which as a person I tolerate much more in spoken speech than written one. Still, I liked the comment, but agree it could have been improved.
I'm comfortable reading much more than two paragraphs, even in online forums. In this specific case, unreadability is because of poor sentence structure. I quit in the middle of the second sentence.
You aren't holding it wrong, the truth is AI is a mixed bag, leaning towards a liability.
If people really counted all the time they spend coddling the AI, trying again, then trying again and again and again to get a useful output, then having to clean up that output, they would see that the supposed efficiency gains are near zero if not negative. The only people it really helps are people who were not good at coding to begin with, and they will be the ones producing the absolute worst slop because they don't know the difference between good and bad code. AI is constantly trying to introduce bugs into my codebase, and I see it happening in real-time with AI code completion. So, no you aren't "holding it wrong", the other people are no different than the crypto-bro's who were pushing blockchain into everything and hoping it would stick.
Imagine you are a JS dev and github comes out with a new search feature that's really good. it lets you use natural language to find open source projects really easily. So whenever you have a new project you check to see if something similar exists. And instead of starting from scratch you start from that and tweak it to fit what you want to do.
If you were the type of person who makes tiny toy apps, or you worked on lots of small already been done stuff, you'd love doing this. It would speed you up so much.
But if you worked on a big application with millions of users that had evolved into it's own snowflake through time and use, you'd get very little from it.
I think I probably could benefit from looking at existing open source solutions and modifying them a lot of the time, and I kinda started out doing that at first. But eventually you realize that even though starting with something can save you time, it can also cost you a ton of time so it's frequently a wash or a net negative.
Nothing you described in this comment is only achievable with "AI". I've been able to search for and find open source projects since forever, and fork them and extend them, long before an LLM was a glimmer in Sam Altman's beady eye.
No it’s not at all. AI just makes finding it faster. But that’s my point AI isn’t that different from what you could already do before. Most of us didn’t do things that way before, so maybe programming like that is just a bad idea.
I've started "racing" Claude when I have a somewhat simple task that I think it should be able to handle. I spend a few minutes writing out detailed instructions, which I already knew because I had to do initial discovery around the problem domain to understand what the goal was supposed to be. It took a while to be thorough enough writing it down for Claude, which is time I did not need to spend if I had just started writing the code myself - I'm sure the AI-bro's aren't considering the time it takes just to write down instructions to Claude vs just start coding.
So then Claude starts discecting the instructions. I start writing some code.
After a while Claude is done, and I've written about two or three dozen lines of code. Claude is way off, so I have to think about why and then write more instructions for it to follow. Then I continue coding.
After a while Claude is done, and I've written about three dozen more lines of code. Claude is closer this time, but still not right. Round 3 of thinking about how Claude got it wrong and what to tell it to do now. Then I continue coding.
After a while Claude is done (yet again), and I've written a lot more code and tested it and it's working as needed. The output Claude came up with is just a little bit off, so I have it rework the output a little bit and tell it to run again.
I downloaded the resulting code Claude wrote and compared it to my solution, and I will take my solution every single time. Claude wrote a bloated monstrosity.
This is my experience with "AI", and I'm honestly not loving it.
It does sometimes save me time converting code from one language to another (when it works), or implementing simple things based on existing code (when it works), and a few other tasks (when it works), but overall I end up asking myself over and over "Is this really how developers want the future to be?"
I'm skeptical that these LLM-based coding tools will ever get good enough to not make me feel ill about wasting my time typing instructions to them to produce code that is bloated and mostly not reusable.
What's your definition of "working"? Do you consider it working, when you have to put more effort into prompting back-and-forth than writing it the old way?
I honestly think the people who love Claude were not super proficient coders. That's the only thing I can think of to explain why writing gobs of English and then code reviewing in a loop could be easier than just coding yourself.
We are not talking about economic theory. We are talking about house prices. Time after time it has been seen that free-enough market can lower the prices to affordable levels.
The relative abundance of land compared to other factors of production is, in fact, such a proposition. But when land is restricted through zoning laws this stops holding true. In other words, we must eliminate restrictions on production for the benefit of all people, but particularly the poorest.
We don't need economic theory for that it's just common sense. Humanity has been erecting structures to live in for approximately our entire existence. The modern economy is mechanized. How could a wood frame structure or a small high rise possibly be unaffordable if the market is functional?
Stop and think for a second. Someone in good health with a willingness to DIY and a sufficiently flexible schedule can literally build their own house from the ground up. It's a substantial time investment but not actually as much as you might think. Housing isn't very resource intensive compared to the rest of the modern economy.
The only possibilities I can imagine to explain unaffordable housing are broken regulations, critical levels of resource exhaustion, natural or man made disaster, and gross economic dysfunction.
It's regulations. But before you call them broken, some of it is safety. Safety standards keep rising with technology and the economy as people can afford more. Same with cars. There's also zoning restrictions in some places designed to prevent slums by requiring large residences. I guess that's happening here too.
Also living standards, ancients houses are dead simple and today could probably be built with usd 5k-10k in a couple months. But most people wont accept a home with no electrity, no lights, no AC, no indoor plumming, etc.
The average person would need a MASSIVE investment in time to learn all the skills required in addition to investment in tools. Furthermore people won't lend joe random the funds required in the same fashion as they would for an actual finished house OR constructing a house via a contractor.
I reported a similar case of mine several days ago [0]. I was able to achieve better quality than Claude Code's 624 lines of spaghetti code in 334 lines of well-designed code. In a previous case, I rewrote ~400-line LLM generated code in 130 lines.
This better reflects what I thought about the other day. You either, let clankers do its thing and then bake in your implementation on top, you think it through and make them do it, but at the end of the day you've still gotta THINK of the optimal solution and state of the code at which point, do clankers do anything asides from saving you a bunch of keypresses, and maybe catching a couple of bugs?
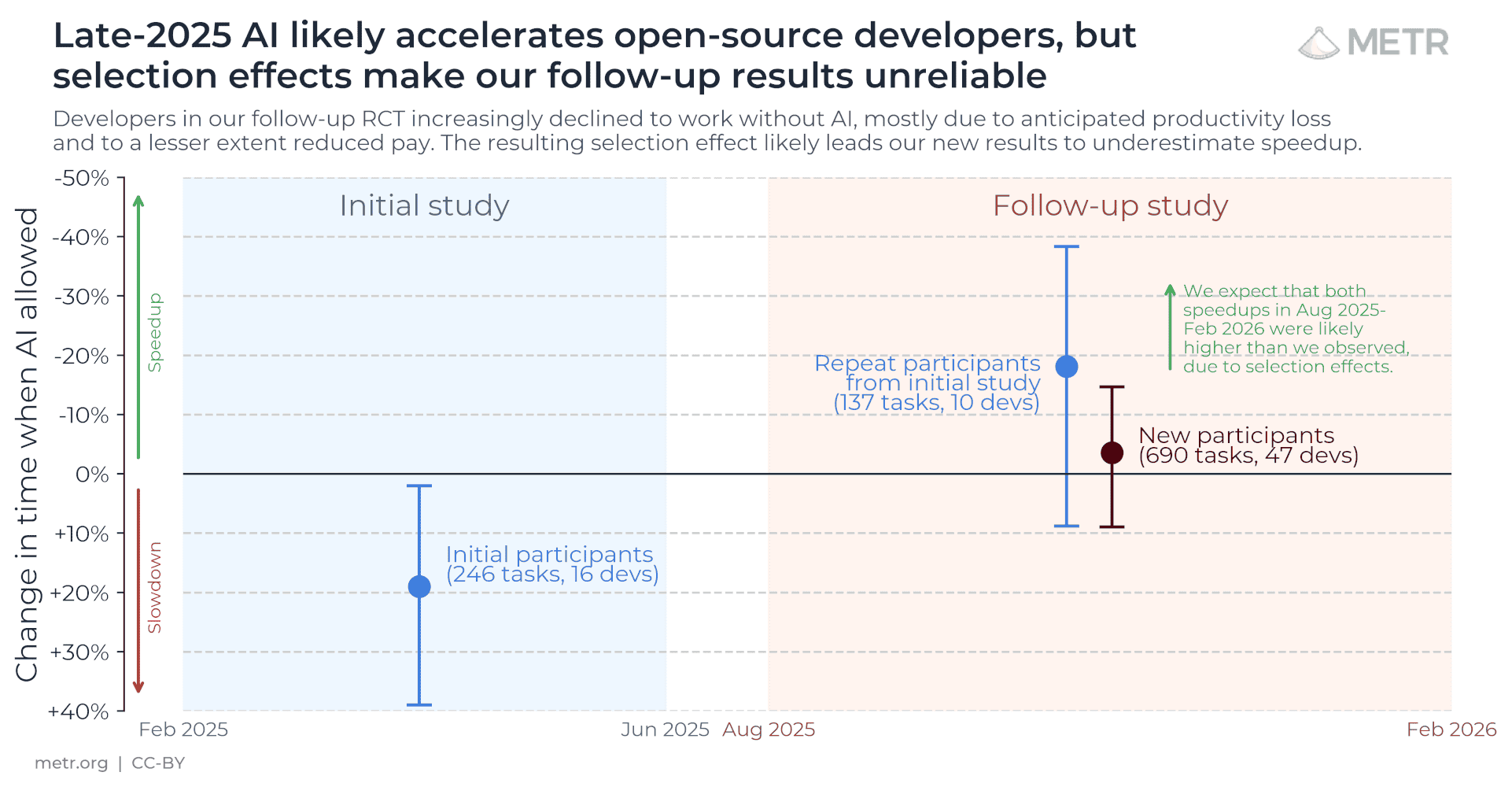
That update blog is funny. The only data they can get at reports slowdowns, but they struggle to believe it because developers self-report amazing speedups.
You'd get the same sort of results if you were studying the benefits of substance abuse.
"It is difficult to study the downsides of opiates because none of our participants were willing to go a day without opiates. For this reason, opiates must be really good and we're just missing something."
My bad, I messed up by being lazy while switching from decreases in time taken (that they report) to increased in throughput. (Yes, it's not just flipping the sign, but as I said, I was being lazy!) The broad point still holds, their initial findings have been reversed, and they expect selection effects masked a higher speedup.
I did my own experiment with Claude Code vs Cursor tab completion. The task was to convert an Excel file to a structured format. Nothing fancy at all.
Claude Code took 4 hours, with multiple prompts. At the end, it started to break the previous fixes in favor of new features. The code was spaghetti. There was no way I could fix it myself or steer Claude Code into fixing it the right way. Either it was a dead-end or a dice roll with every prompt.
Then I implemented my own version with Cursor tab completion. It took the same amount of time, 4 hours. The code had a clear object-oriented architecture, with a structure for evolution. Adding a new feature didn't require any prompts at all.
As a result, Claude Code was worse in terms of productivity: the same amount of time, worse quality output, no possibility of (or at best very high cost of) code evolution.
Are you able to share your prompts to Claude Code? I assume not, they are probably not saved - but this genuinely surprised me, it seems like exactly the type of task an LLM would excel at (no pun intended!). What model were you using OOI?
The exact same prompt ? Everything depends on the prompt and it’s different tools. These days the quality and what’s build around the prompt matters as much as the code. We can’t feed generic query.
Imagine you are stranded in your home with all your loved ones, and you get a call from your "warmonger" president and the matter is urgent; he says "We have received intel regarding a enemy plan to bomb your house in 30 mins. This report is only x% reliable, but we have the exact location of the enemy and we have birds in air that can hit them in 5 mins. This might escalate into a larger conflict, Do you want us to proceed? "
What would your response be? What is the value of `x` at which you will approve of the pre-emptive attack?
What is your percentage to say no lets do not take actions. Because again; with this perspective every single action is legitimate. There is a chance for everything. If there is a weapon that can kill every human on the planet, every country will race to invent it because every country will try to invent it. Every action is valid. Every weapon development is okey, because if you dont, others will. You can kill everyone, because everyone might eventually try to kill you, there is always a chance.
We both know that it is not true. Because by this logic, you wouldn't fire a weapon at someone who is about to stab your wife or child. Because there is a small chance that they will die of a heart attack before they can do it. So it is some value that is < 100%, but apparently that is not good enough for you.
You did not accept my answer and did not answer to mine as well.
On top of that, while you are pulling some hypothetical scenarios, the reality is exactly as I described. Governments, especially us gov, kept invading, bombing and killing people based on some subjective percentages and this is still ongoing.
Although you did not like my ‘prefer to die instead of kill’ idea, you still did not solve ‘you can kill everyone since there is a chance anyone can kill you’ problem. And reality is closer to latter, unfortunately.
>What does objectivity have to do with the value of x?
It does not have anything to do with objectivity. I thought it to be futile to discuss that since, as you implied, predicting future can't be 100% objective, and thus decisions to avert a bad future outcome always need to be based on subjective decisions.
So this is another question where I want to ask you how you would make a subjective call.
{kind=link}
No, it's not. When you see `p.Age`, you have to go back and find the body of the loop, see what it operates on and decipher what p stands for. When you see `person.Age`, you understand it. I've never understood what is gained by using `p` instead of spelling it out as `person`.
reply