> No more will photographers or even ordinary people have to fumble with aperture size and exposure length.
This is a "computer scientists" understanding of photography, and this phrase alone can even be seen as "dangerous" by photographers. There's more to aperture size and exposure length than "how much light reaches the sensor", like focus, depth of field, motion blur and bokeh, to name a few, that is not aknowledged by that understanding. The technology is good, but it won't change the way photographers deal with photography, at best, it will give them a better tool to work with.
I also wonder how much impact this could have. Foveon Inc. had developed a great sensor that was going to be revolutionary, about 20 years ago. Today only Sigma uses it, and the UX is so bad in those cameras that the (very good) technology they had their hands on never got a chance to shine.
Also, is this implementation very different from having a 16-bit ADC in normal sensors? The end results would be the same: higher dynamic range. And the increase in bits seems a lot closer (because it would mean little changes to the current manufacture processes) than a whole new type of sensor being use in cameras.
I'm surprised no one in the comments so far has used the word "clipping", which is what the real breakthrough here is in. I've been doing street photography somewhat seriously for about five years now, and always shoot full-manual: I rarely have problems with motion blur because I control the shutter speed; I rarely have problems with focus because I use assisted manual; the only thing that gets me with any regularity is highlight or shadow clipping.
I often shoot with a histogram overlay which helps a lot, but there are still high-contrast scenes where I have to decide where I'm going to bias the exposure. I can usually tease out some more detail in Lightroom from the RAW file, but direct sunlight plus shadow, or a quick-draw moment where I fumbled the exposure to make the shot, often leave some clipped areas.
Not having to worry about clipping would be an amazing breakthrough, and I'd even accept some other limitations in a camera that could manage this.
FWIW, analog film doesn't clip in the same way as digital, but instead has a nonlinear roll-of on either end of the brightness scale. Still there is a limit to the maximum contrast, of course.
If you're interested, try Tri-X for BW and Fuji Velvia 50 for color. Any late 70s Nikon will do well as a camera, the old 50mm f1.4 is particularly good and cheap. Tri-X is best developed yourself, but the Velvia needs sending to a lab that specializes in positive film development.
> This is a "computer scientists" understanding of photography, and this phrase alone can even be seen as "dangerous" by photographers.
The actual headline of the article is actually more informative and less misleading than the subhead:
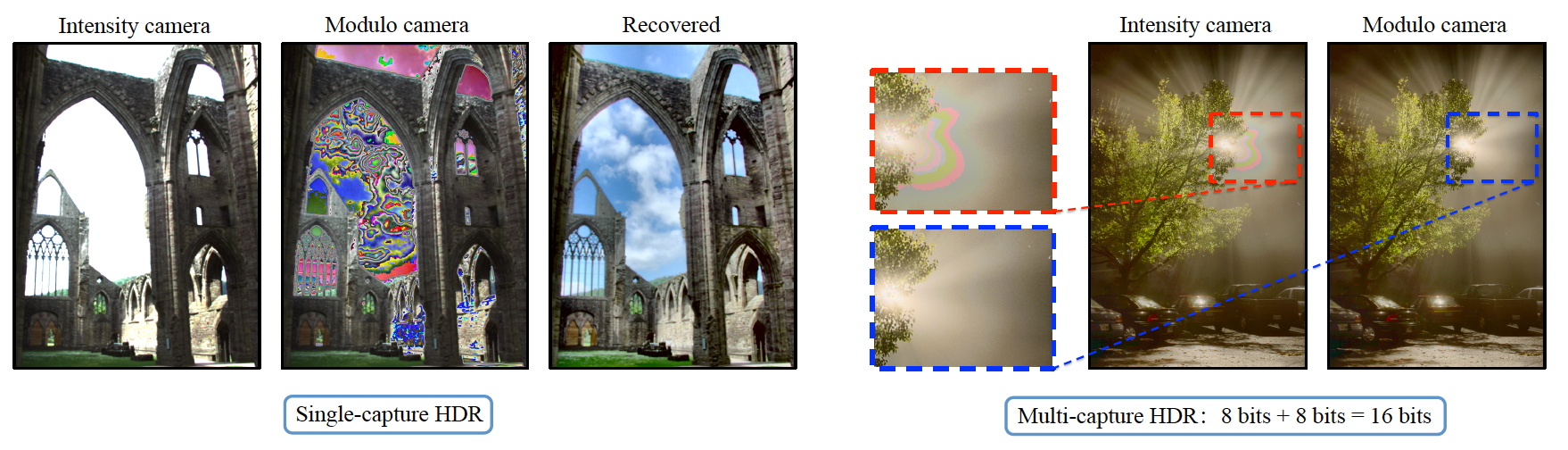
"Unbounded High Dynamic Range Photography Using a Modulo Camera"
In photographer's terms, they're referring to ending blown highlights (caused by filling the wells in a sensel) not saturated images (caused by exaggerating color data).
There's a school of photography that basically lives and dies by over-saturating images (e.g. http://kenrockwell.com ) and they'd likely have a cow over the headline, but understand and be totally onboard for the actual goal.
Depending on how quickly the well can reset and how many times resets can be counted this will either be better or worse than simply improving existing approaches. The state of the art in full frame sensors is just under 15-bits of dynamic range. So to equal it an 8-bit sensor would need to be able to count resets at least 128 times AND be able to do this in 1/8000 of a second, at the same sensel density and efficiency! Don't hold your breath.
(I'd also suggest that trends towards using multiple sensors to assemble high resolution images will easily blow this away since they can use high- and low- sensitivity sensors to synthesize more dynamic range and resolution. Also see recent Olympus patents to capture polarization data at the same time.)
BTW: assuming they can do this stuff, they presumably can read the sensor pretty darn fast — so they should be able to eliminate image "tearing" in digital video and the need for mechanical shutters altogether. That's probably a bigger issue than dynamic range.
I suspect that clearing a well in < 1/10,000,000 of a second (which would only lose 10% of the photon detection time during a 1/8000s exposure) is going to be tough. Assuming 25% of the sensel real estate needs to be sacrificed to the modulo circuitry, that's a loss of 32.5% of photon data which is about the same loss as for pellicle mirrors (as seen in Sony's pretty unsuccessful SLT cameras) for a feature that won't be much use in many situations.
> There's a school of photography that basically lives and dies by over-saturating images (e.g. http://kenrockwell.com ) and they'd likely have a cow over the headline, but understand and be totally onboard for the actual goal.
Actually, I suspect that even that crowd, after the initial shock would be absolutely on board. This would mean that no longer would the sensor control how the high-end clipping happens, but now that could be tailored specifically via a post-processing filter. E.g. to exactly match a long-gone film emulsion's behavior, "enhance" a classic, or to simply to create new clipping functions.
This is a bit analogous to the flexibility that black and white shooters gain by working with modern color sensors. When shooting B&W film, the tonal result was controlled via a combination of the film's spectral response and any colored lens filters applied, the latter used to manipulate tonal contrast between different colored subject matter (e.g. sky, plants, skin tones, etc.). Now a skilled photographer can shoot color RAW w/ B&W preview (for a preview of the image luminosity) then adjust in post to nail the image effect without having to mess even thinking about what colored lens filter(s) to have used.
Good point -- if this worked even moderately well -- e.g. it lets you capture 20 bits of DR -- a photographer could go crazy with the old film approach of "expose to the right" and simply keep settings such that every shot is "over" exposed and simply fix it all in post (it's pretty hard to over-expose by more than 6 stops unless you're trying...)
To emulate film stock we need a solid 14-bits of Dynamic range (while DxO says the D810 has it, the article below says 11-bits, but the best video cameras are getting there):
Ideally we'd get something like this AND capture polarization data as well (per the recent Olympus patent). Then you can apply polarization and exposure correction in post.
I identified the same issue with cycle time, but to me the biggest problem is the assumption of an accurate, sensitive, non-destructive-read sensor. They're assuming that they can charge a capacitor from a photodiode accurately, and also hook a voltage comparator (which is effectively the same as an ADC) to it constantly to get an accurate pulse to count.
Assuming you have an accurate sensor that can be read non-destructively, then none of this modulus stuff is necessary anyway. Read once to set the proper gain on the ADC, then read again to get the fine bits. That way you still get the "unbounded HDR", but you don't need an ADC for every single receptor site, and you don't waste space on the counter or comparator. Instead, all of that lives on the image processor where it's not going to cause heat noise.
That's such an incredibly enormous hand-wave to me that I feel I've got to be missing something. Why make it so complex with all the modulus stuff if we have a magic sensor?
And we haven't even gotten into issues like thermal noise... Who knows, it may be great, but right now it just looks like a press release :-)
Oh the 1/10,000,000th comes from assuming they need to reset 128 * 8000 times per second to merely equal current sensor performance before losing sensitivity to misc losses.
If they want one more bit of DR they need to cycle in half as much time, and so on. Similarly, if we generously assume they're only losing 50% efficiency to cycle time and real estate then double again.
Also don't forget that you actually need to cycle significantly faster than just 128 * 8000 times per second, since presumably you can't integrate light into the capacitor while you're also zeroing it. Whatever goes into the capacitor while it's draining is lost, because it drains to zero.
Seems like a better approach would be to add a "gain pixel" to traditional sensors.
So imagine you've got your Bayer grid (or a layout that functions similarly), one of the pixels in the grid gets read out first. That one sets the gain for the ADC for the surrounding pixels. The downside is your iteration couldn't be linear and the gain control would be a lot more complex, but you could do it with technology that actually exists, and you wouldn't lose half of your vertical resolution by doing it a whole line at a time like Magic Lantern's dual-ISO mode.
You'd have to do fancy processing around high-contrast edges, but what else is new.
All good points. (And my figure actually assumes 10x faster and no loss of time between clearing wells and capturing photons -- i.e. 90% of time is spent capturing photons and 10% is spent clearing the well with no downtime -- to be generous. And, again, just to equal current performance.)
The underlying idea is sound -- storing bits is a linear problem but storing photons is an exponential problem. Of course you're still going to have to dump exponential amounts of energy... (So forget the "unbounded" part.)
Yeah I was thinking that too. No matter how tiny a capacitor, you have (tens of) millions of them on the sensor, one per photoreceptor, and you're charging and discharging them 100k-10M times per second. That's a lot of energy being accumulated and dissipated right next to the photoreceptors. Thermal noise is gonna be nuts on a modulus sensor, too.
No system is ever unbounded, period, unless you live in a world of frictionless spherical cows. At some point you run into issues caused by accuracy, energy, capacity, etc.
Consider that writing to a DRAM cell -- which involves charging or discharging a capacitor -- takes a few nanoseconds. This is at least four orders of magnitude faster than your estimate of 100µs.
Actually they're not so much faster -- although the camera companies don't have the economies of scale to iterate nearly as fast as the phone companies (so they hang onto a processor generation for a couple of years).
A good smartphone can capture 4K video or 20fps 8MP or whatever off the sensor — both around 160MB/s. A $10k DSLR is handling 16MP at 11fps — that's around 300MB/s (remember that the DSLR is handling 14-bits per sensel).
The interesting thing is that if you look across the camera lineups, there's almost no difference in CPU between a $300 consumer camera and a $10k professional (there is a big difference in RAM - the DSLR is able to store 50+ uncompressed images in RAM (let's say 3-4GB), while the phone or low end camera processes them into JPEG before storage.
You might be conflating cpu processor speed with, what is essentially "io" (light as an input, I'd suppose) and basically waiting for physics to happen.
It sounds from the implementation summary that it's equivalent to a higher bit-depth ADC, but that the higher-value bits are inferred by software somehow. I don't think it would properly recover an image with a dark field with the exception of a single pixel with a value of 10^7 above the dark noise.
What would truly solve the dynamic-range problem is a logarithmic readout CCD.
(Thanks for the Foveon pointer; it's an elegant approach to color.)
It's actually inferred by hardware - the paper handwaves it because they wanted to focus on the software, but basically they're talking about implementing a low-accuracy micro-ADC at every site that automatically wipes the charge when it hits a trigger voltage and counts every time it does so. Number of counts = site signal level.
Not quite sure that's practical or how you'd implement it on a destructive-readout sensor, though. Right now the sensors with enough accuracy and sensitivity are all destructive.
The Foveon sensor is different - the claimed benefit there has to do with stacked silicon and lack of debayering, and the benefit is having better resolving power with the same pixel count. Sony is now researching similar stacked chips so we'll probably see this idea return.
The innovation with the tech in the article is in the dynamic range, current CMOS sensors have a fairly limited maximum dynamic range because of the well saturation described in the article, usually around 12-14ev DR. For high contrast situations that isn't enough, and photographers will definitely appreciate increased dynamic range, not to mention the other applications they listed, like astronomy.
On the display side most displays also have fairly limited DR and cannot reproduce the dynamic range in HDR images, so we end up having to tonemap images to get the perceived dynamic range back - however I think HDR monitors will break through in the next couple of years as many HDR TVs are hitting the market this year.
Worth noting that those "HDR" televisions are still only Rec709 which is limited to about 6 stops of dynamic range. Sure some are approaching rec2020 color gamut, but we're still cramming all that gamma down into 6-9 stops. Even a consumer DSLR can shoot 12.
I work in post and have moved our workflow over to the Academy Color Encoding Specification (ACES) which supports up to 27 stops (more than the eye can see which is about 24 best case scenario). ACES allows us to dynamically change our output to rec709, rec2020, P3 etc and while 2020 has better colors, it's definitely still a highly compressed image (in terms of dynamic range).
I'm actually not convinced most people will want 5-100x brighter pictures than we currently have! Dynamic range of the human eye is also related to foveal/peripheral vision, so dynamic range in the real world probably doesn't map 1:1 to a small screen experience - if that makes sense.
I am very interested in "natural", halo free tone mapping algorithms, squeezing that extended DR into current displays. I really like the results Adobe is getting with laplacian pyramids in Camera Raw for highlight/shadow recovery. Do you know of other tone mapping algos that look natural?
I don't work with much HDR so I can't help you there.
As for file formats, it varies entirely on the show. Higher end, fx heavy shows tend to use DPX and occasionally openEXR while lower end shows are typically some flavor of ProRes (422HQ and 4444 being nosy common). DNxHD 175 or 220 are also occasionally used. Some people are trying to move to the new ProRes high quality (4444XQ or DNxHR).
Delivery specs for whatever network are almost always ProRes 422HQ 720p or 1080p. Features we'll output to DPX or TIFF which will be converted to DCP (JPEG2000) in the P3 color space (XYZ instead RGB or YUV).
I'm excited to see higher bitrates for delivery, but it's going to be a long time on the broadcasters end. They're wary to upgrade so soon - especially when a lot of people already have trouble telling 720p from 1080p.
Indeed, I know what you've written and I agree with it -- writing it all in the first place would've resulted in a wall of text! I'm still unsure if there's a real benefit in this technology, or if the same result can be obtained by increasing the bit precison in the ADC stage of a "normal" sensor.
Even if there were, I pointed at the Foveon X3 as an example of a very good technology that was regardarded as a breakthrough but didn't really make it commercially. Another "revolutionary" idea that was marketed as something that "would change the way we take photographs" were the Lytro cameras, with their unique focus technology, that works by taking the picture in a different way than a classic camera, wich allows to change the focus of the picture working with the "raw" file. Even though that technology is also very interesting, it has remained in a niche market and only offered by one company -- more novelty than "mainstream" photography.
Yes, it's a shame Foveon wasn't a commercial success, the quality in some areas is close to medium format. You can pick dp Merrill's up on ebay for about $300, would be tempted if it could do half decent video too.
I don't think Lytro will ever take off in the way they intended, but light field capture will be very hot for 3D360 VR in a couple of years, when we start seeing first light field goggles (like Magic Leap)
> is this implementation very different from having a 16-bit ADC in normal sensors
16-bit ADCs increases tonal granularity in the readout, which can help in the darker tones. A sensor site may be capable of differentiating about 12 bits worth of meaningful information, hence there's a good argument for overshooting that in the ADC. Our eyes, even if not sensitive to more than 8 bits worth of tonal gradation, are perceiving in a logarithmic space (vs. the sensor recording in a linear space), hence extra information in the shadows can be quite good. Plus the extra bits give more room in which to tune a captured image. An article such as http://www.scantips.com/basics14.html gives a rundown on this.
The extra bits don't help if the incoming light exceeds the sensor's recording capacity, hence the interest of this "modulo" discussion for over-exposed images.
Sure, photographs will still control aperture and exposure time — this just removes a constraint at one end: if you want shallow depth of field and motion blur, you could use this method (and get extra bits) rather than an ND filter.
Exactly. This is huge, and I was wondering why people didn't do it already. Or, for example, why don't cameras currently take multiple snapshots of the sensor? For example, if I'm exposing for 2 seconds, read the sensor at 0.1 sec (for the very bright lights) and again at 2 seconds, for the darker parts. That way, I can make an HDR image without having to take another photo.
Is reading the sensor destructive to the data, somehow?
A sensor with per-pixel reset to zero on readout would seem to be ideal — then you could get cumulative counts without wasting valuable photon landing space on the die.
Of course - that's the current standard way to produce HDR photos. The advantage here is being able to do it all in a single image, which prevents mismatches between images due to subject or photographer movement.
Yes, but if I understand correctly, unless those images occur at the same time (or really, really close) you run into issues involving subject and camera motion.
Because the images would look funny. Imagine you're capturing someone running - at frame 1, they would be at position x, and at frame 2, they'll be at position x + 1. If you try to stack them together, you'll get a weird ghosting effect.
Motion blur, but different parts of the image would be exposed differently due to the nature of HDR, resulting in an odd look. Imagine instead of a runner, that you're panning from a dark to light scene.
That's just really a completely misguided statement. No mater how much you fumble with aperture and shutter speed there's simply no way to expand the camera sensor dynamic range without taking multiple exposures.
Besides I have never seen "ordinary people" fumble with aperture size and exposure length so that's a solved problem. Sometimes it gives "wrong" results, like exposing for the highlights rather than the shadows, that's what this technology solves.
> there's simply no way to expand the camera sensor dynamic range without taking multiple exposures
That's the point of this paper†. They expand dynamic range by having the detectors wrap around (discarding high bits) and then recover the high bits computationally.
> No mater how much you fumble with aperture and shutter speed there's simply no way to expand the camera sensor dynamic range without taking multiple exposures.
Sure you can - you expose for the highlights and then you push the shadows in post with a crazy exponential curve. I do it all the time on digital. People used to do it via print manipulation too (filter grading, split printing, dodging and burning), except back then you exposed for the shadows and controlled the highlights (since you were capturing a negative, not a positive).
What would normally have been indistinguishable blacks are pushed into the midtones and you get a flat, grainy image. It just looks like garbage because noise gets out of hand and you lose all your color depth, but there's more dynamic range there in the sense of there being more stops of light crammed onto the final image.
There is a physical limit of the camera or the film where you cannot actually squeeze any more accuracy out of the ADC, but standard conditions are nowhere near that limit.
Some DSLRs and MILCs (and I think some semi-pro compacts too) have a wide enough dynamic range that they can work and HDR image from a single RAW file. Catch is, you have to shoot RAW and then process it with specific software. When it's done in-camera, it always is through multiple exposures. Even without specific software, you can work the effect from a single RAW file to get "multiple exposures" from it and then combine them into an HDR image.
The title here is terrible because over-saturation is an effect of poor tone mapping, which is inevitable if you want to display an HDR image in a low dynamic range display. An accurate title would be the end of over-exposed images, but why not just keep the original?
I'd guess whoever wrote the article subtitle comes from an EE or DSP background, where saturation refers to blowing out the ends of the dynamic range and clipping/distorting.
Looks to be more related to exposure than saturation but still, it's an interesting new take on dynamic range. I'm more a hobbyist than an expert but current tone mapping techniques (at least anything mostly automated) can often leave you with "halos" around objects where the software has feathered the edges between lighter and darker areas. Then the article mentions the issues with using multiple shots for tone mapping.
I still try to just expose "properly" for the effect I want and shoot RAW to give me a little leeway in tweaking shadows and highlights but I'd be interested in trying out software that uses this technique if only for something new to mess with.
Halos are a problem, but they can mostly be removed with good post-processing. Note they're not a fundamental aspect of tone mapping. Tone mapping is just whatever algorithm you chose to compress the HDR information into a low dynamic range we have for displays. The great thing about this camera compared to multi-exposure HDR (apart from the halo effect you mentioned) is you can actually take pictures of moving objects or even make HDR movies (the temporal variation should actually help with better phase unwrapping). That would be amazing for the film industry I think.
Out of curiosity, with regard to video, what would be the difference between what you describe and a nicer version of the sort of processing used in (for example) some Axis security cameras? I guess the current method is just to capture a decent range and then process each frame to boost the gain on shadows and lower the gain on highlights, right? Sort of an extension of quick-and-dirty HDR on still photos.
Either way, this is the sort of stuff that has always interested me about photography and videography. The creative aspects are obviously the end goal for most people (myself included) but I've always been a sucker for the technical aspects of it...the craft to the art as it were. Nothing prompts me to pick up my camera and shoot some photos or some video like learning about some new tool or technique that I want to try out. It may be the mark of the eternal amateur but still enjoyable.
As explained in the article, this is different to combining exposures, which is what conventional HDR does too. The important thing to consider here is how does this scheme affect the SNR of the sensor. This scheme encourages keeping essentially maximum possible sensitivity (ISO), but this "modulo sensor" circuit may introduce some additional noise.
I am probably less technical than most of you but the upside of this technology (at the point it is real world ready) might be producing what I would call a RAW file that is RAW(ER). By that I mean the file would simply contain a wider range of scene information that could be accessed by Adobe Camera Raw or the like. For the class of photographers that have no interest in RAW the information would help the JPEG engine in the camera make a "better" informed JPEG (or whatever the standard is at that time). To me capturing more scene info is better than less assuming there are minimal penalties being paid elsewhere (file size, burst shooting etc).
As a side note, it seems to me that aperture and shutter speed would still be essential as they affect not only exposure but depth of field and subject motion. Perhaps a technique that allows proper exposure independent of fstop/shutter/ASA would allow exploration of extremely wide aperture with slow shutter but no need for ND filters.
In any event it will be interesting to see what happens.
It seems like this would make big glass even more important. This solution protects for over exposure, but doesn't address under exposure on a scene that moves (think indoor bar photography). So it isn't a end all solution that will everyone capture reality with their cell phones, but it is an awesome step in that direction.
I had an idea similar to this that solved the oversaturation issue.
Use 2 cameras. Have them at right angles to the shutter point, separated a few inches. At the T junction where the camera pointing would cross with the shutter area, put a prism there.
The prism would give each camera 1/2 of the available photons. Now use any standard HDR processing technique.
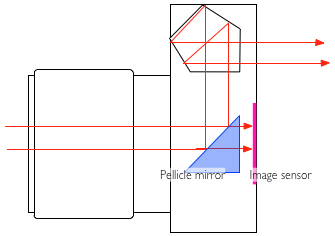
Interestingly enough that's how Technicolor used to work. Three separate exposures from a single lens, split off by pellicle mirrors.
The downside is that like any pellicle you are dividing your light between multiple exposures, meaning you some mixture of a longer exposure, a faster lens, or more lighting. Technicolor required special high-intensity arc lighting. Also, the pellicles must be kept spotless because dust shows up on the final image.
Next-gen sensors will actually implement this physically - some receptor sites will be larger than others.
Admittedly, my understanding of traditional optics is very limited. I happened upon it in a dream whilst trying to figure out how to handle dynamic scenes while using SLAM.
I was thinking of a prism (new word: pellicle mirror) like this one :
Except I don't need the deconvolutional prism. I can handle that in software easily with a X or Y matrix flip. And I assume we are using the same CCD module for both areas; given that, I can sum the contrast between the pixels and calculate the min and max, as well as can calculate the HDR image from both sources.
Calibration would be easy to handle, using a checkerboard to link the CCDs to each other (assume aligning errors will happen).
I also see no reason why the pellicles wouldn't be kept clean. The same goes for the CCDs as well. I'd embed them in a dark acrylic box and try to seal them as best as can be.
The acrylic box blocks all your light (dark is bad), and now you have to keep THAT clean instead. Any surface in your optical path needs to be kept clean, but especially those that are between the center of the optical system and the sensor. Dust on the front element doesn't matter too much, dust on the rear element matters a lot and pellicle mirrors are even worse since they're closer to the focal plane. Scratches from cleaning are real bad too.
As long as your lens system is sealed it's not a problem. But many systems are interchangeable-lens, and when the lens is removed then dust can float in. Or some lenses generate a "vacuum" effect as they focus in and out.
Sensors often incorporate an ultrasonic motor which vibrates it and throws dust off. Or some sensors are mounted on shake tables to reduce blur from operator motion - you can do a similar thing there too. At the end of the day you just have to be careful though.
Like I said, totally possible optically, and yes, very simple to process. The downsides are that when you split the beams each sensor only gets half the light intensity, which means you need to get more light into the optical system in the first place, and you need 2 sensors, which are by far the single most expensive component in the whole camera.
You can actually do something similar with Magic Lantern, a hacked-up open-source firmware for Canon cameras. They scan alternate rows of the sensor at different sensitivities, and use the low-sensitivity row as the most-significant-bits of dynamic range for the high-sensitivity image. You lose a bunch of vertical resolution, but hey, you don't need 2 sensors.
I wonder how this compares to just adding a few extra bits to the sensor data. The paper (http://web.media.mit.edu/~hangzhao/papers/moduloUHDR.pdf) compares against an "8-bit intensity camera", but most cameras today use 12-16 bits internally. Isn't "this pixel overflowed" essentially just an extra bit of information?
The pictures using the "modulo camera" are definitely better quality, but don't look noticeably better than what I could do with a RAW from my camera and 2 seconds in Capture One or Lightroom adjusting the shadows and highlights.
As a photographer who at times needed to deal with HDR this is great news. In the past, I had often wondered why some scheme like this wasn't possible.
However, the title of this post is horrible. I understand they were trying to market it in a way it was accessible to most readers. That said, photography has become quiet popular and most people now understand HDR. So they could have just presented as true HDR with only a single frame image.
Read about something like this on http://image-sensors-world.blogspot.co.uk a while ago - instead of saturating the CMOS when max brightness is exceeded, it just keeps going.
This is a great idea. It would be interesting to see the failure modes though because the phase-unwrapping surely can't handle every situation (e.g. adding a constant value >255 to the whole image).
Here's an idea, instead of separately tracking the number of "resets" we just add those bits on to the left hand side of the measurement. We could call it... having more bits in the ADC. Expose for the highlights and then pull more detail out of the shadows with your extra bits of ADC precision.
There are not 1 million ADC units in a 1-megapixel camera, there's a few ADCs (a Canon 7D has 2 image processors with 4 ADCs each) that are iterated across the CCD sites to progressively read them out. To make this new sensor, you need to cram 50 million sets (50mp is state of the art) of voltage comparator/charge reset/digital counter circuits onto the CCD, and for N bits of rollover accuracy they need to be able to trigger, erase the charge, and resume exposure at least N times during the exposure time E (which is say 1/500th of a second, since they're complaining about movement during multiple HDR exposures). Practically speaking the trigger/operation/resume period must be significantly less than E/N since I see no way to retain the exposure during the period when the charge well is being drained to zero. If this time is non-trivial, that translates to losing the fine bits of your ADC accuracy.
In their image they compare a 13-stop exposure (the current state of the art) to an 8-stop exposure (state of the art in 1900). So assuming they didn't just pull a photoshop out of their ass, they are overall claiming a 5 stop increase from state of the art. That's 5 extra bits of recovery (1 stop is double the range, i.e. an extra bit), so they think they can trigger the reset circuit 5 times during an exposure. That implies this circuit must have a minimum cycle time of 1/2500th of a second (practically speaking a lot less to give time for the actual exposure). With this math I'm also assuming that the comparator is perfect and doesn't lose any accuracy - variance in trigger threshold or trigger time translates to losing some of your accuracy again. They also need to generate little enough waste heat to avoid hot pixels (this is a major reason the ADC is on the image processor rather than the CCD), and you need 50 million sets of these on the CCD.
If you can do it then go for it. It's a nice idea on paper but I think there's a lot of physical obstacles to overcome. If it were that easy someone would have done it already. It's especially difficult given that reading out the sensor is destructive - measuring it wipes the charge, so I'm not sure how any of this would work at all given that.
Now what would actually be interesting is to apply the image-processing techniques to dual-DR imaging, as they mention in their "related works" section. The open-source Magic Lantern firmware for Canon DSLRs allows you to scan alternating rows at different ISOs, so effectively you can capture a lot more dynamic range at the expense of your vertical resolution. It's all volunteers and they probably haven't applied all the fancy image-processing magic with the convolutions and the hippity-hop rap music. How about reconstructing those overexposed lines instead? Or working on some of the sensors with physical implementations of dual-DR?
I'm not sure what you mean by self resetting pixel designs. Do you perhaps means the self-shuttering (rolling shutters) on CMOS sensors?
This is very different. If you oversaturate either a self shuttering sensor or a shuttered CCD, that information is gone. All you know is that this is "100% bright, or more". Your software which turns raw sensor readings into an image makes the area full brightness, and you get blow outs.
With this approach, say the light is bright enough to make a pixel read 567% (if that as possible). A standard sensor would record 100%. This sensor would empty itself five times and record 67%. Then, the algorithmic magic happens which looks at neighboring areas and figures out how many roll-overs happened and adds the 500% back in.
You can't do that perfectly (hence my comment before about an overexposed zebra), and it will introduce new forms of aliasing, kind of like de-bayering the bayer masks makes moiree patterns.
I've seen CMOS pixel designs in the past that can detect saturation and effectively dump the well (reset) repeatedly until saturation no longer occurs.
A related, but quite different technology I worked with are so-called Dynamic Vision Sensors (DVS, [1]): This is a CCD that was developed to mimic a biological retina and only reports changes in brightness, asynchronously for every pixel. Essentialy, you get a stream of short messages saying "Pixel XY just got a little brighter at time T".
While such a thing is not very useful for taking pictures (pointing the camera at a static scene will generate no output at all) or videos (you don't get discrete frames, you get a continuous stream of differentiated pixels), it has a lot of potential for computer-vision tasks:
For one, as the camera only reports changes, only the interesting information is transmitted which greatly reduces computational load (eg. no need for "yes, that white wall is still there"-style calculations for every frame).
Secondly, because these changes are reported independently per pixel, they are very fast: Microsecond accuracy with a dozen or so uS delay are easily achievable. For comparison, a fast camera with 120 FPS (which will produce a lot more data to process) has an accuracy and latency of 1/120s = 8333uS. This also implicates that motion blur is basically nonexistent.
And thirdly, as absolute intensity doesn't matter, you don't have any problems with high dynamic range either.
The only downside is, that you don't really get a picture and most of the traditional computer-vision approaches are unusable ;)
But still, such a camera is very neat, even if you just track the movement of your mice or want to balance a pencil on it's head[2].
The real deal however is full vision based 3D-SLAM, which would allow for very fast and robust movement without any external help from motion capturing systems or expensive (in money, weight and power) sensors like laser scanners. AFAIK, we're not there yet (see [3] for some work in that direction), but that would bring pizza delivery with a drone directly to your desk quite a bit closer to reality...
{kind=link}
{kind=link}
This is a "computer scientists" understanding of photography, and this phrase alone can even be seen as "dangerous" by photographers. There's more to aperture size and exposure length than "how much light reaches the sensor", like focus, depth of field, motion blur and bokeh, to name a few, that is not aknowledged by that understanding. The technology is good, but it won't change the way photographers deal with photography, at best, it will give them a better tool to work with.
I also wonder how much impact this could have. Foveon Inc. had developed a great sensor that was going to be revolutionary, about 20 years ago. Today only Sigma uses it, and the UX is so bad in those cameras that the (very good) technology they had their hands on never got a chance to shine.
Also, is this implementation very different from having a 16-bit ADC in normal sensors? The end results would be the same: higher dynamic range. And the increase in bits seems a lot closer (because it would mean little changes to the current manufacture processes) than a whole new type of sensor being use in cameras.